Changelog
Below is a comprehensive list of all changes made to the project. Automatically updated every day.
Have a feature request or bug report? Please reach out to us on the livechat.
See what we are planning to ship in the roadmap.
3 months ago
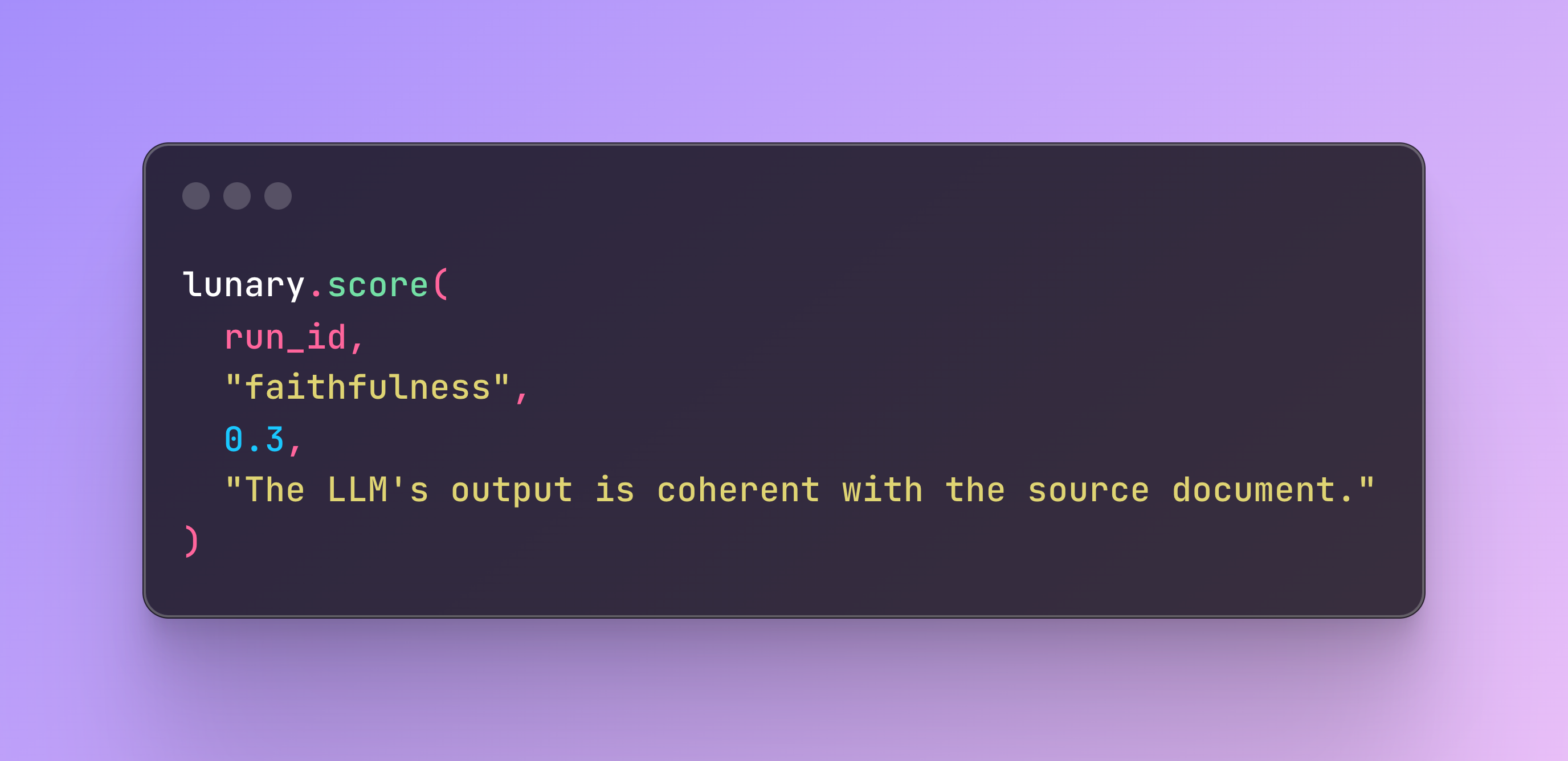
SDK scoring for custom evaluations
New! See the results of custom evaluations and scoring ran from SDKs in the dashboard.
3 months ago
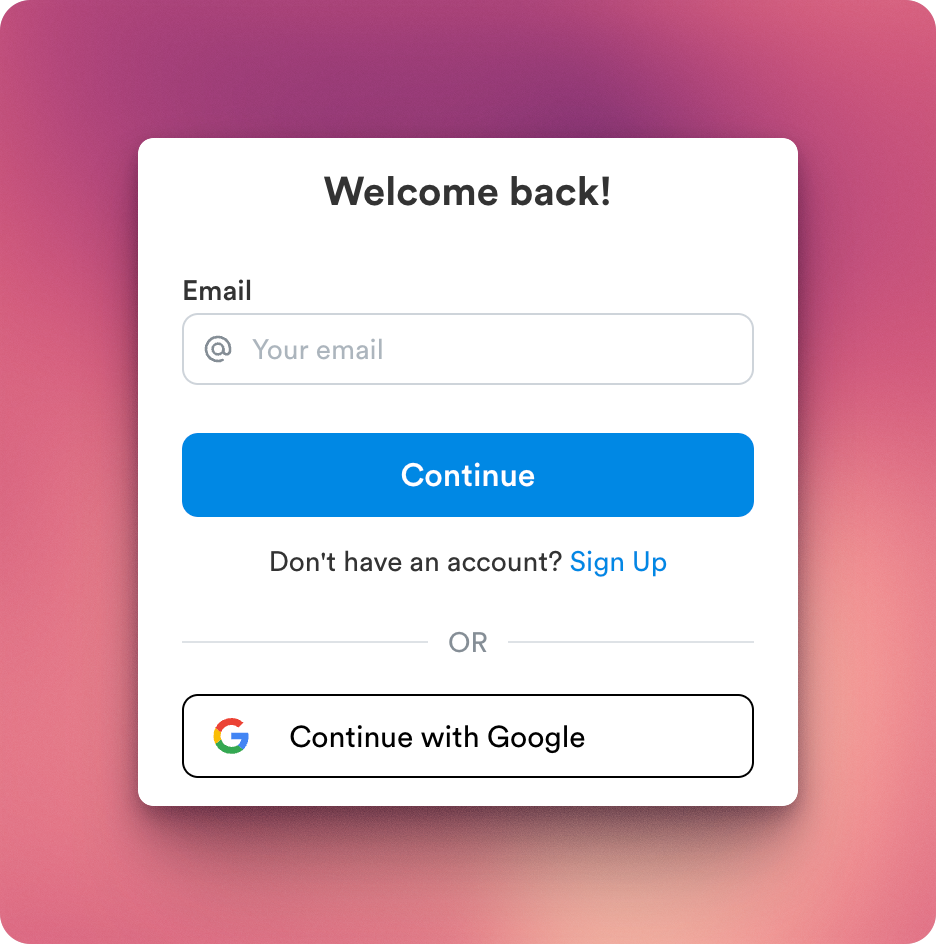
Log in / Sign Up with Google
We made logging in Lunary even easier with a Google Integration.
3 months ago
Improved blog design
We've redesigned our blog layout to make reading articles more friendly.
4 months ago
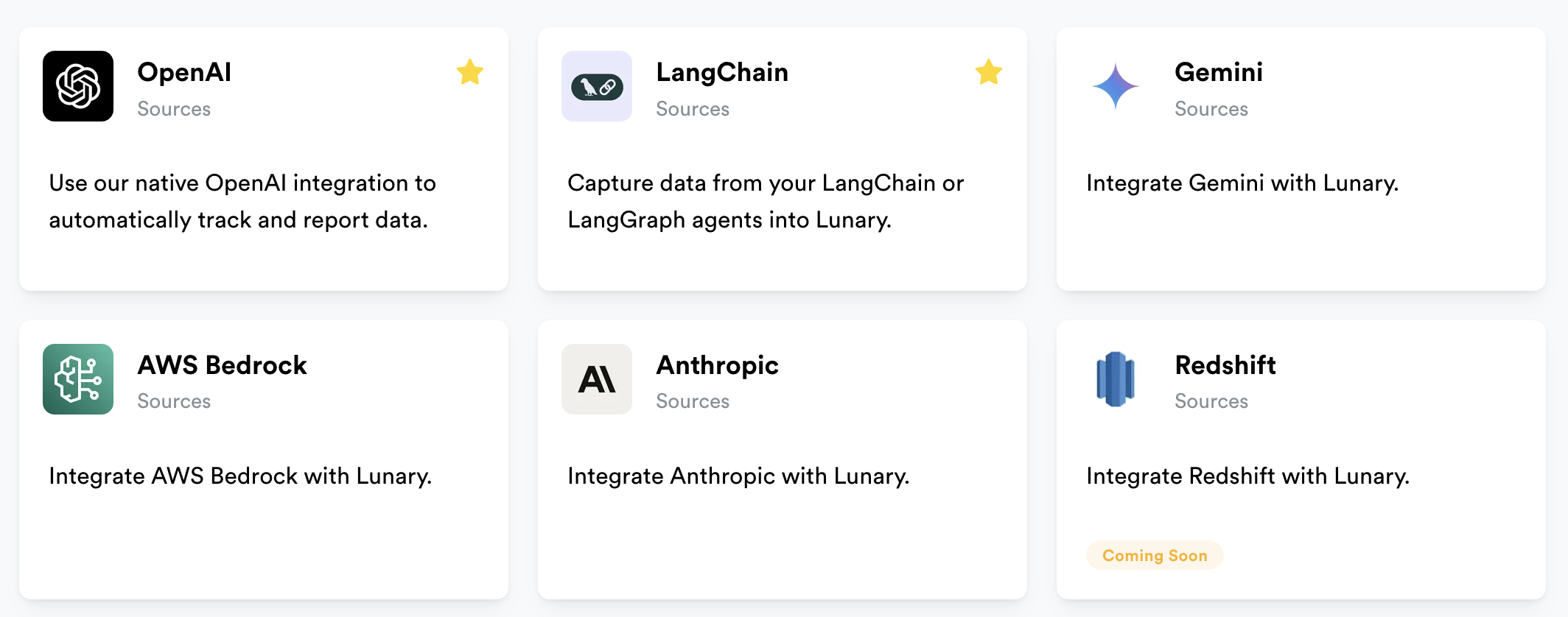
Integrations page
4 months ago
Documentation for all API resources endpoints
API routes documentation is now available at https://lunary.ai/docs/api
5 months ago
SMTP support for self-hosted deployments
You can now add your own SMTP credentials for sending emails from your self-hosted Lunary deployments.
6 months ago
Allow custom inference API keys for LLM evaluators
7 months ago
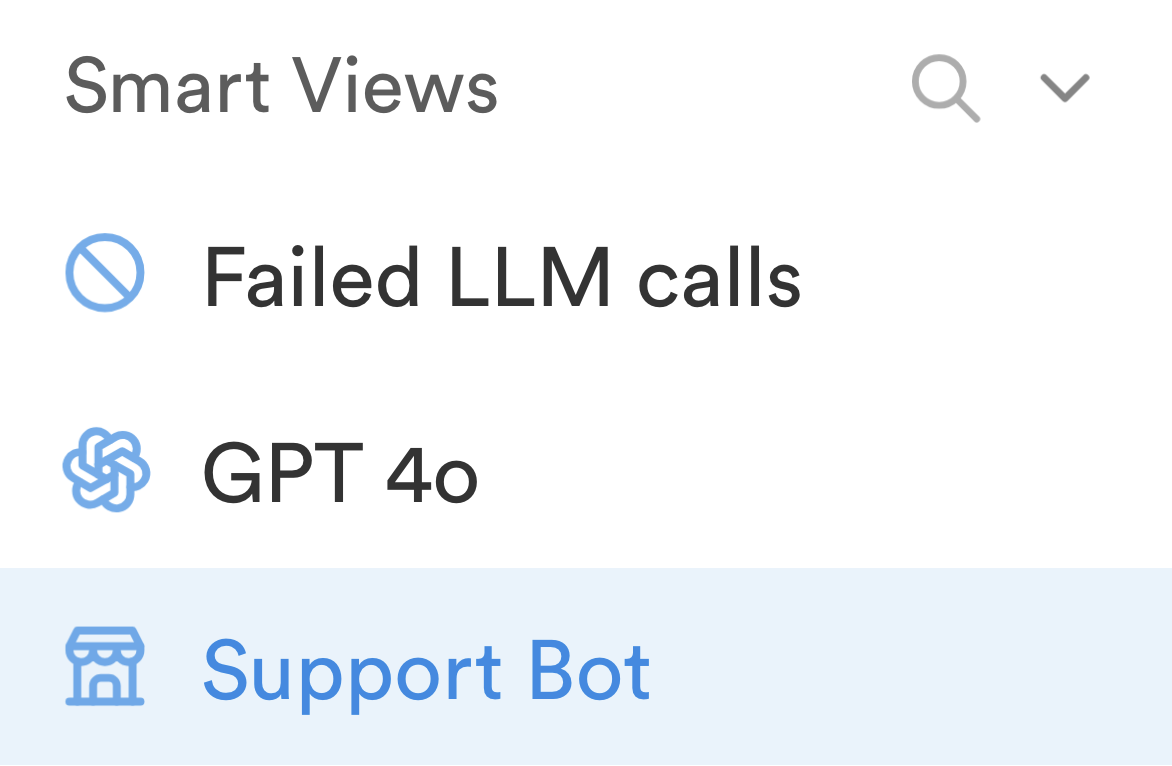
Saved Views
Saved combination of columns and filters into reusable views.
8 months ago
Remove OpenTelemetry dependency from Python package
9 months ago
GPT support assistant
We're experimenting with a new support assistant to assist with common requests and help our small team regain focus.

