Documentation
Getting Started
Integrations
JavaScript
Python
LangChain
API
Others
Features
Observability
Prompts
Threads
Evaluations
Radars
Users
Feedback
Tags
More
Security
Concepts
Self-hosting
Evaluations
Evaluations let you run logic against LLM responses. They help you benchmark models and prompts to find the best for your needs.
If you're interested in evaluating LLM responses you've already captured, take a look at our radars product.
Example ways to use evaluations:
- Benchmark an LLM response against an ideal answer using cosine similarity
- Find the cheapest model that fits all conditions
- Ensure responses don't leak sensitive customers data
- Ensure responses are not too long or too costly
You can create evaluations on the dashboard by picking models and conditions:
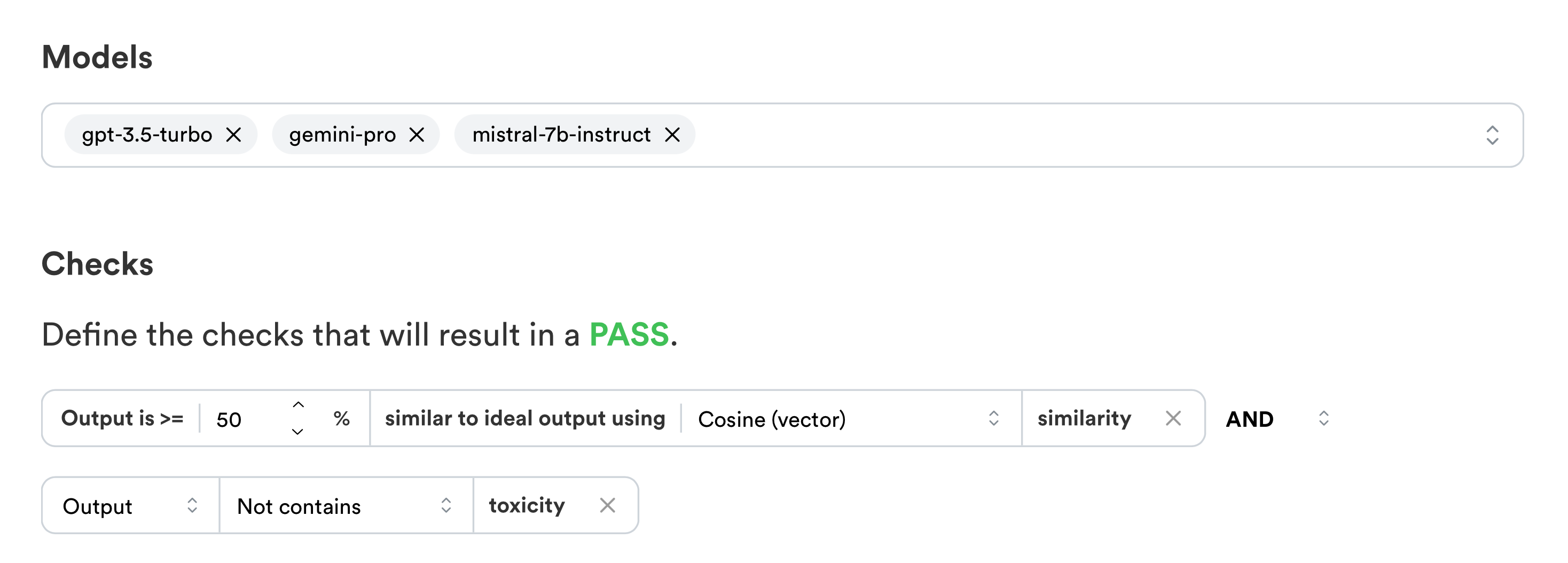
Evaluations can be created and ran on the dashboard automatically with 20+ models, but they can also be setup to run directly in your code for advanced usecases or in your CI pipeline.

